Title:
DeepRacer: Dynamically Adapting to Waypoints for Optimal Heading in Autonomous Racing
Group Members: William Rivero, WSU DeepRacer Team
Program Enrolled: Bachelor of Computer Science
Supervisor: Bahman Javadi
Introduction:
This project explores a reward function for AWS DeepRacer that dynamically adjusts based on waypoints, optimizing the vehicle’s heading for more efficient autonomous navigation. The objective is to test whether this approach outperforms centreline-following strategies by promoting a direct path that reduces travel time.
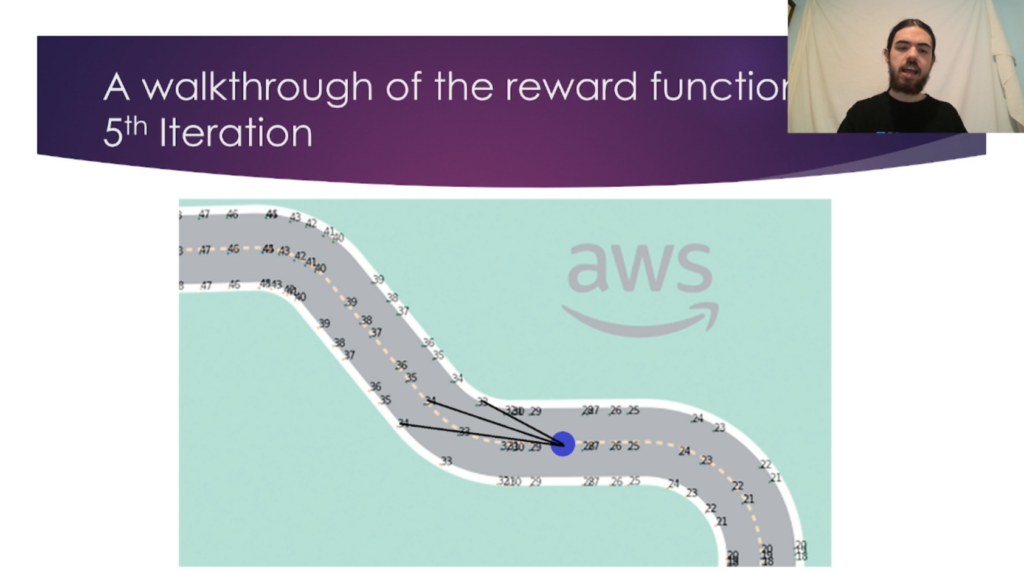
Method and Technology Used:
The project iterates through the waypoints ahead of the agent, identifying the optimal angle for the agent’s heading. Using reinforcement learning, the reward function penalizes deviations from this angle, encouraging a direct, efficient path. Three models, each utilizing different reward functions (optimized heading, distance from centreline, and centreline heading), were trained and evaluated on time-trial completion time over 30 laps each. Training spanned up to four hours, with AWS DeepRacer serving as the platform for training and evaluating models in a 3D racing simulator.
Results:
Initial tests showed the optimized heading model underperformed due to off-track penalties. However, after additional training, it surpassed other models, proving the reward function’s effectiveness in reducing lap times.
Conclusion:
This project demonstrates the potential of dynamically optimizing vehicle heading to enhance efficiency in autonomous racing. The results indicate that a reward function centred on optimal heading can outperform traditional centreline-following approaches in reducing lap times when given sufficient training to improve its performance.